
Catalog errors in FRBR-ized discovery layers
When a public library moves to a FRBR-ized discovery layer, it needs to be more careful with catalog errors.
The most recent discovery layers for public library catalogs can group individual items in different formats under a single title. That is, the discovery layer has been "FRBR-ized". We'll see that this and other features can result in some problems, particularly how it magnifies the effect of poor catalog data.
I'll discuss four discovery layers:
Aspen Discovery (at Montgomery County Public Libraries, Maryland)
Vega Discover (at Washington County Free Library, Maryland, The Ferguson Library, Connecticut and MidPointe Library System, Ohio)
BiblioCore (at Las Vegas Clark County Library District, Nevada)
CARL•Connect Discovery (at Frederick County Public Libraries, Maryland)
The four systems are not all alike. Vega Discover is the most different, heavy on thumbnails (e.g., cover images and author photos) in addition to text, and displaying subject headings as "topics" and "concepts". CARL•Connect Discovery is the most conventional, based solidly on MARC records.
Introduction
How are items grouped?
The FRBR work-expression-manifestation-item bibliographic model (referred to using the abbreviation “WEMI” [1]) is just one of three models that helps to understand what each discovery layer does.
Each discovery layer also has a model that determines which items are grouped and which are separated. Their model is closest to E-M-I. All kinds of "books" (books, large print, ebooks and audiobooks) are grouped into an "expression" but movies are treated separately. That's not totally unreasonable from a patron perspective. Unfortunately, the discovery layers refer to the groups as "works", which I don't think is strictly correct, but since it's common usage, I'll follow it.
Patrons have an internalized model that maps roughly to W-E-M-I, but with different boundaries. For patrons for example, different editions of the same work in the same format probably count as "the same thing", although in most (all?) library systems different editions would be different bibliographic records.
Which is how a discovery layer can end up with this (from BiblioCore):
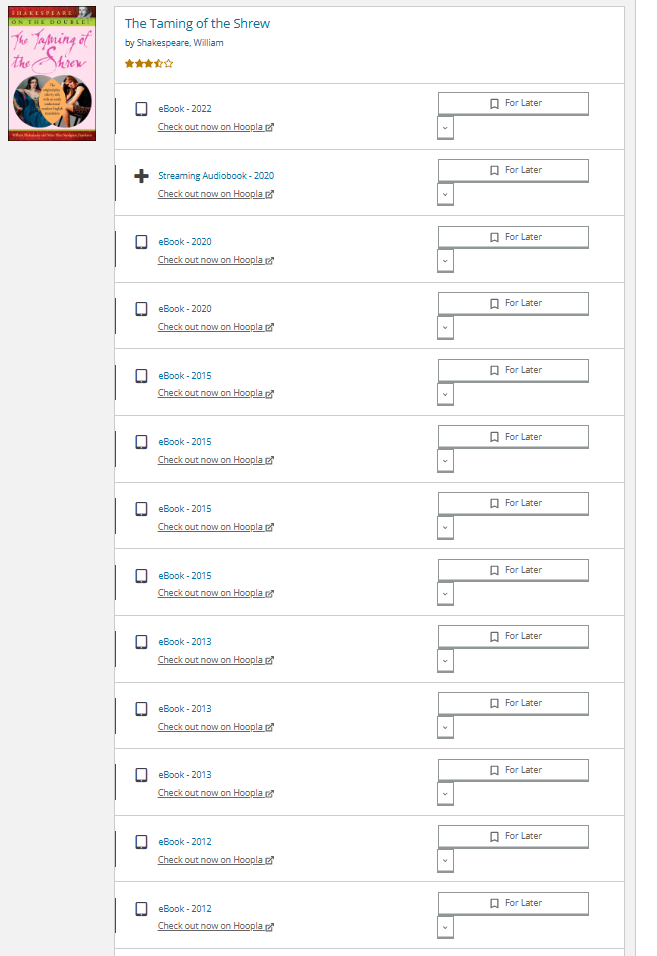
[Note: If you're reading this on GitHub, you can see any image full-size by clicking on it.]
This is not helping the (public library) patron one bit. Even someone who cares about the exact text — a student or actor, for example — is forced to click through to each item in turn to find the particular edition they're looking for.
Vega does better with this situation:
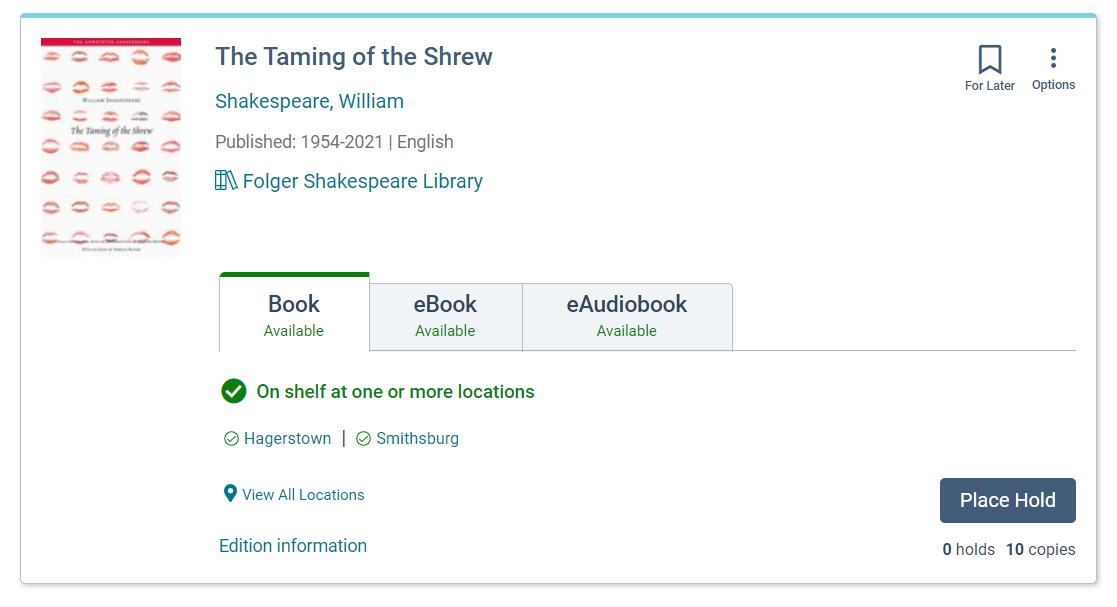
where information on individual editions is hidden behind a clickable link — much closer to a patron's internal bibliographic model. Aspen Discovery has a similar feature.
Clickable fields
Suppose we're looking at the item page for a book by Robert Wilson. There are several Robert Wilsons (which is why I'm using him as an example). Let's assume we're looking at a book by "Wilson, Robert, 1957-". The page includes a clickable field for "Robert Wilson". But what does the link do? What do we want the link to do?
In some systems, the link might perform an author search for "Wilson, Robert", in some an author search for "Wilson, Robert, 1957-". In some newer systems, the link might link to the specific author who wrote the book we are looking at. The link might look something like:
mylib.thevendor.com/author/750347935782where the number is an identifier, internal to the system, for a particular author. In this case, the system has the opportunity to format the web page differently than the usual search results page. This is how Vega produces custom "author pages" (and "concept pages" in place of a subject heading search).
Any place a system displays a thumbnail image, that can also be clickable in the same way.
Catalog Enhancements
All four discovery layers pull in "catalog enhancements" from external sources:
BiblioCore -- Novelist [2]
Aspen -- Novelist and Syndetics Unbound
Vega -- Syndetics Unbound
CARL•Connect -- Syndetics Unbound For example, if you click on "See all related resources" in Vega, the browser collects data from each of the following domains in addition to the catalog:
iivega.com
syndetics.com
librarything.comincluding multiple subdomains such as unbound.syndetics.com, as well as fonts from google and tracking from pendo.io.
Displaying works vs items
The different systems have different ways of displaying a grouped work on a "work page".
BiblioCore and CARL•Connect are similar. They display one item at a time, and you can switch from item to item using buttons (BiblioCore) or tabs (CARL•Connect). For example, here's CARL•Connect displaying a work that includes both book and ebook formats:
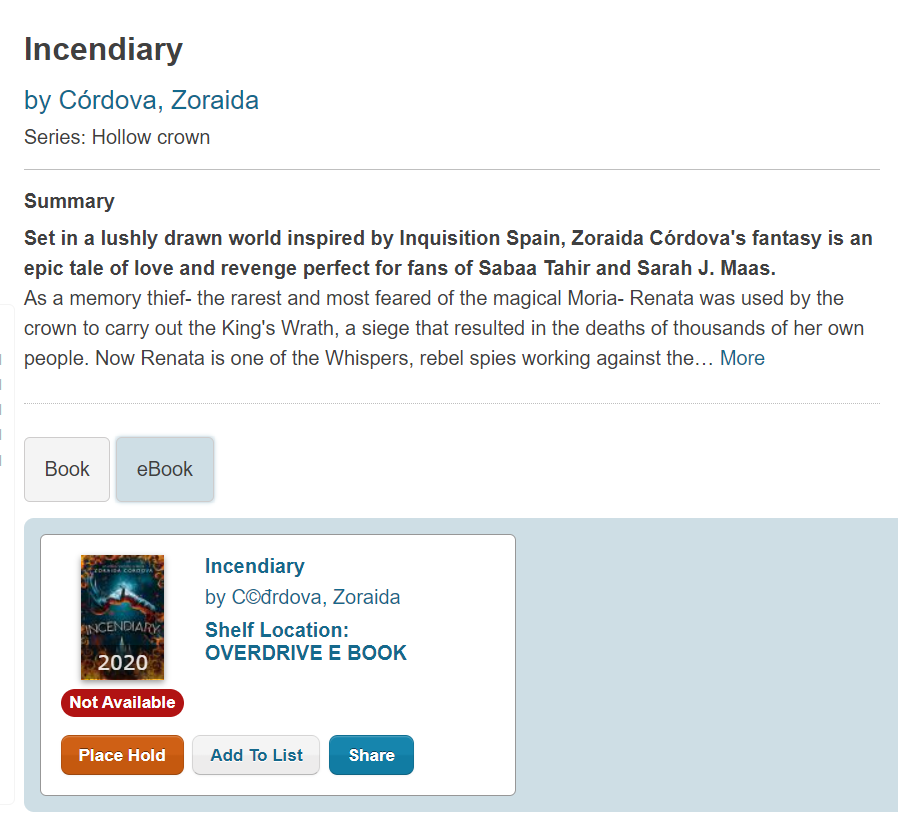
When CARL•Connect builds a "work" out of a set of bibliographic records, it simply selects one of the records (nominally the most reliable) to represent the work. Thus, when the work is displayed, the information displayed (author, title, etc.) is from that record. You can see in the screen shot above that the ebook has a garbled the name of the author but the primary author entry at the top of the screen is correct, since it's taken from the book record.
Aspen Discovery, on the other hand, combines the information from the records of the multiple items that make up the work. We'll see some problems with that approach in what follows.
Vega Discover doesn't display any of the underlying data, such as MARC records, so I don't have any visibility into how it's building work pages.
Series information
Series information can come from the MARC record but also from a "catalog enhancement" vendor like Syndetics Unbound or Novelist. In Aspen Discovery, the catalog includes information from both Syndetics Unbound and Novelist.
Series information can be included in the MARC record in the MARC 490 field (transcribed) and the MARC 80X-83X fields (controlled). Because one field is transcribed and the other controlled, it's possible for the MARC record to include two different series names.
So, when we look at the catalog page for a grouped work, we might see series information from multiple places in multiple MARC records as well as multiple external data sources. That's going to be a problem.
Examples
Failing to group items into a work
Each discovery layer promises to group items into a work, but that depends on consistency in titles and author names. One way this can fail is when series information leaks into a subtitle:

This would cause problems in any catalog, of course, since searching on the second title (e.g., by clicking on it) would not return the first title, leaving the patron to conclude that the library did not have the title as a book.
You'd have the same sort of problem if an author name was not properly controlled.
Series Information
As I explained above, Aspen Discover is rolling up information from all the item MARC records, which can produce odd-looking series information like this:
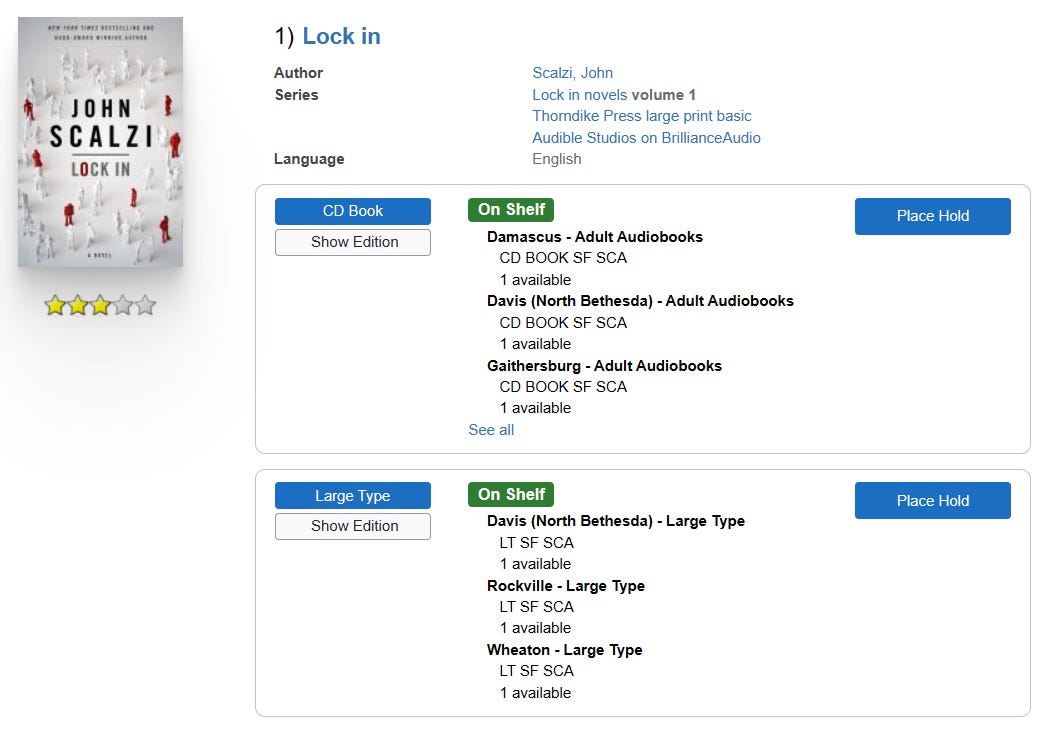
There are a few different problems that are interacting to produce this result. The MARC record makes no distinction between series information about the work, and series information from the publisher (like "Audible Studios on BrillianceAudio"). Similarly, there is no distinction between information about the work and information about the expression. With no help in the MARC records to determine which is which, the discovery layer has no alternative to using everything.
By the way, the series names from Thorndike Press and Audible Studios clearly violate the rule against series-like phrases in LC-PCC Policy Statement 2.12, so the MARC records aren't correct, or at least not LC-PCC-compliant.
You can see the same issue in Vega:
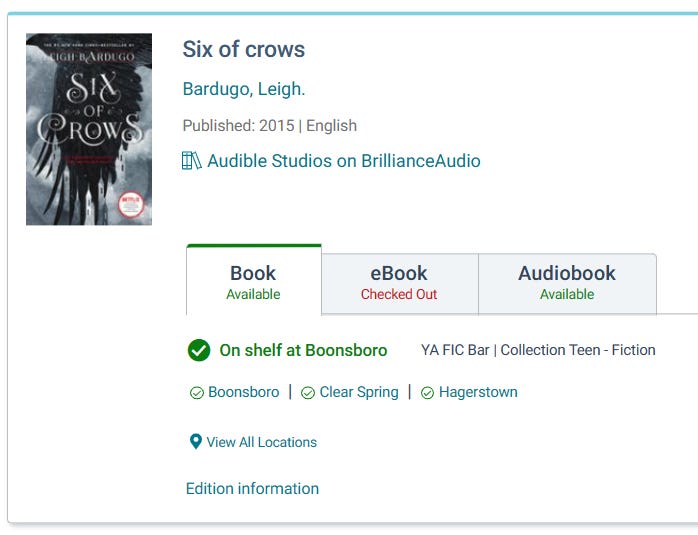
The other problem is that series information can be slightly different in the records for different formats. That's how we get this (from Aspen Discovery):
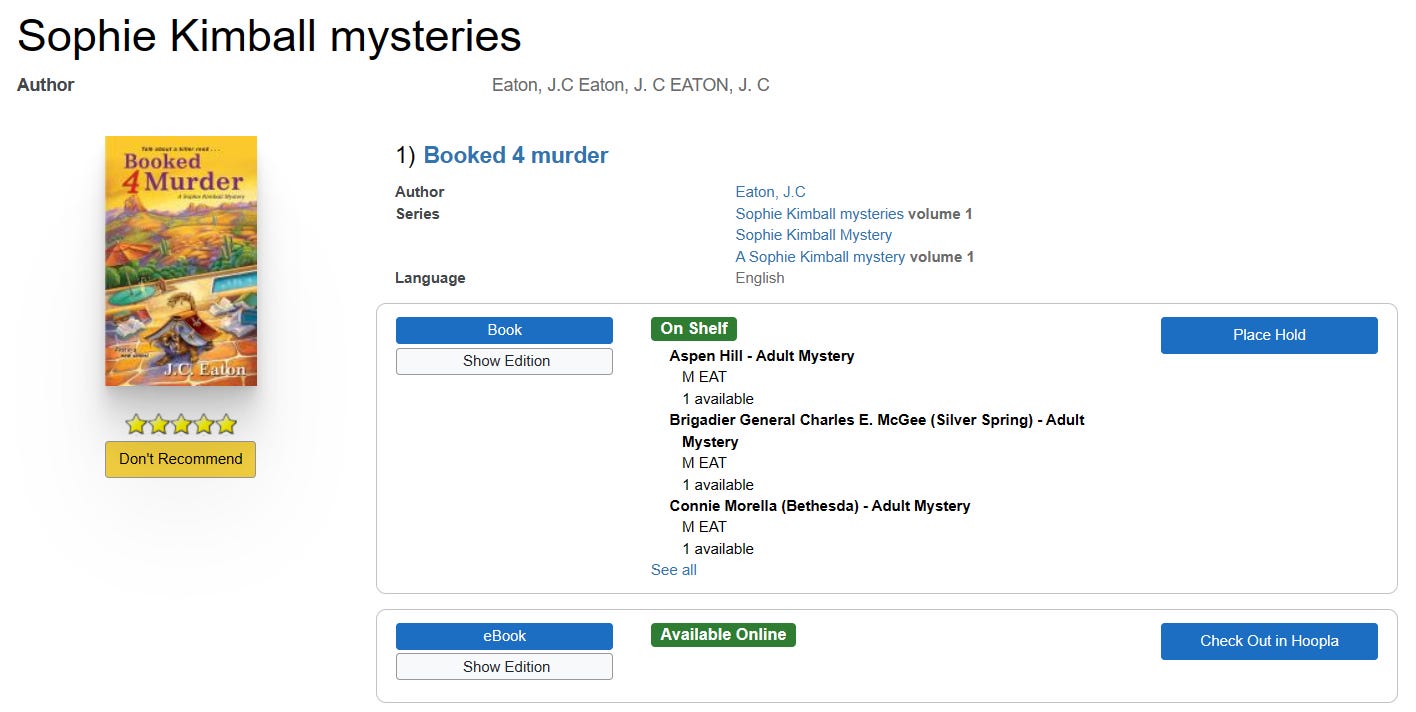
This screenshot is the first item returned when doing a series search for "Sophie Kimball mysteries". Above the first item you can see the result of rolling up different spellings of the author's name from all the results.
On the other hand, Vega is doing something clever with its search algorithm. Here's a search on "The Emma Djan Investigations":
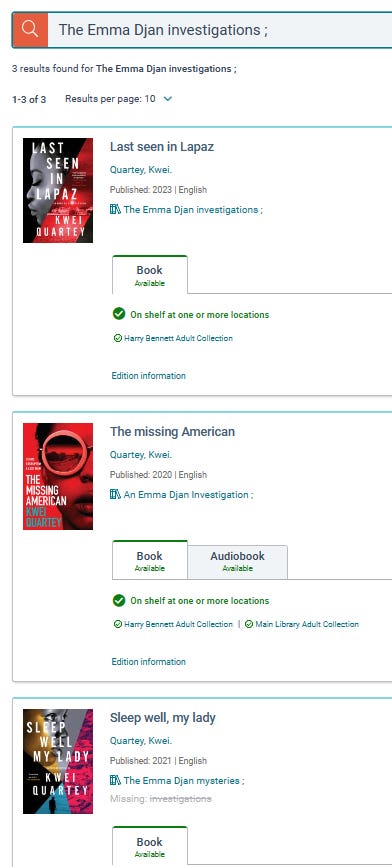
The search has correctly returned all three books in the series, although each book has a different series name, particularly the last book returned, where the series is "The Emma Djan Mysteries".
Enhanced Series Information
As I mentioned above, some systems get series information from Novelist and some from Syndetics Unbound. This doesn't have anything to do with the fact that the catalog is FRBR-ized, but it's worth looking into anyway.
Unfortunately, series information from Novelist is not very accurate. Here's the Lock In series by John Scalzi:
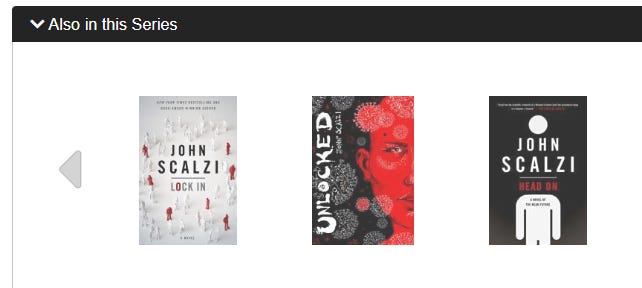
The series order is wrong ("Unlocked" is a prequel and should be first) and there's no indication whether the library actually holds the items or not. (Other systems grey out series members that the library doesn't hold.)
Aspen Discovery is complicated, since it gets series data from both Novelist and Syndetics Unbound. For the Lock In series, it displays incorrect information from Novelist, and correct information from Syndetics Unbound. Unfortunately, the former is always displayed, and the latter is a click away.
There's also the question of what to do with a series that only contains one item. Here is BiblioCore trying to show series information for Notorious Sorcerer by Davinia Evans:
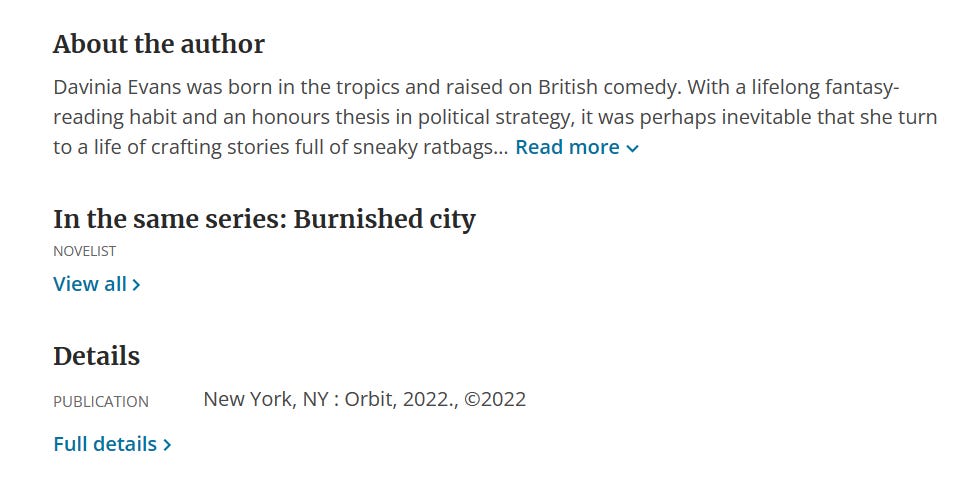
Technically, that's correct: there aren't any other titles in the series. But I'm not sure that's the best way of communicating that fact.
Author and Contributor Names
Author and contributor names come from the 1xx and 7xx fields in the MARC record, which are controlled, as well as the 245 $c subfield, which is transcribed. As usual, there is scope for some confusion between controlled and transcribed information.
The difference between a controlled and transcribed name can be the presence of absence of a birth year, such as "Scalzi, John" versus "Scalzi, John, 1969-". It can also be caused by a name change, such as Elliot Page or Victoria Schwab.
Contributors can be specific to a particular format, such as the narrator of an audiobook. And eresource publishers such as Overdrive can appear in the MARC 710 field and be included in "contributors".
Here's an excerpt from the "work" page for "The Invisible Life of Addie Larue" from the MidPointe Library System (using Vega), demonstrating all of the above:
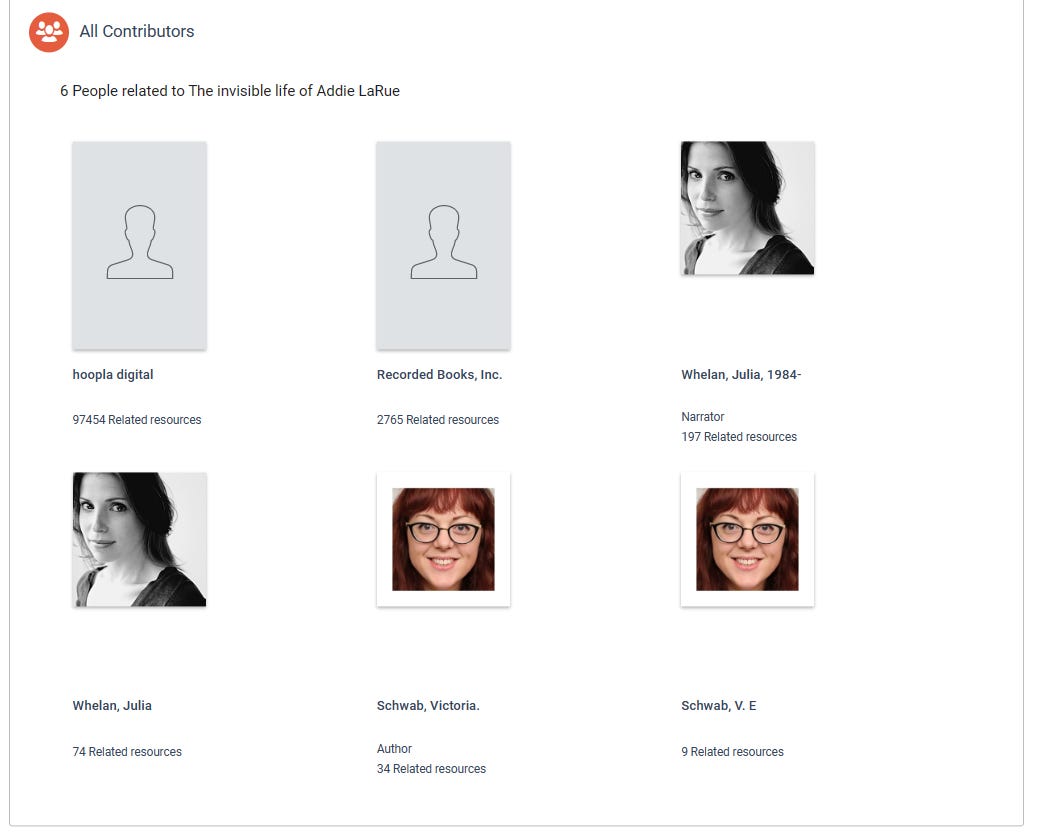
I can't tell where this data is coming from (Vega doesn't expose MARC data on the patron side of the system) but you can see from the resource counts underneath each image that the duplicate identities have different data in the catalog.
We saw above that duplicate series names can be generated by rolling up data from several item records (i.e., items in different formats for the same title). The same thing can happen with author names. Here's an excerpt from the work page for "Naked in Death" by J.D. Robb, from Montgomery County Public Libraries (using Apen Discovery):
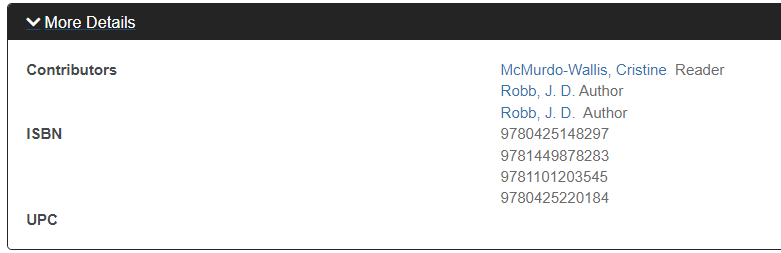
The two author names differ by just one space. Thanks to Aspen's excellent documentation, we can tell what happened. Apen, like other systems, groups items into a single work by author and title. Before trying to match two author names or titles, the names or title are normalized by stripping out punctuation, like spaces and commas. Thus, to the grouping algorithm, the slightly different author names were identical, and were combined into the one work. When displaying the work, not wanting to lose information, both variants were displayed.
Pseudonyms
Pseudonyms can be expressed in MARC authority records, but not necessarily coded to be interpreted by software.
Here's an example of how pseudonyms work in Vega, from The Ferguson Library in Connecticut. JD Robb is a pseudonym for Nora Roberts. Here's an excerpt from the work page for Robb's novel, "Midnight in Death":
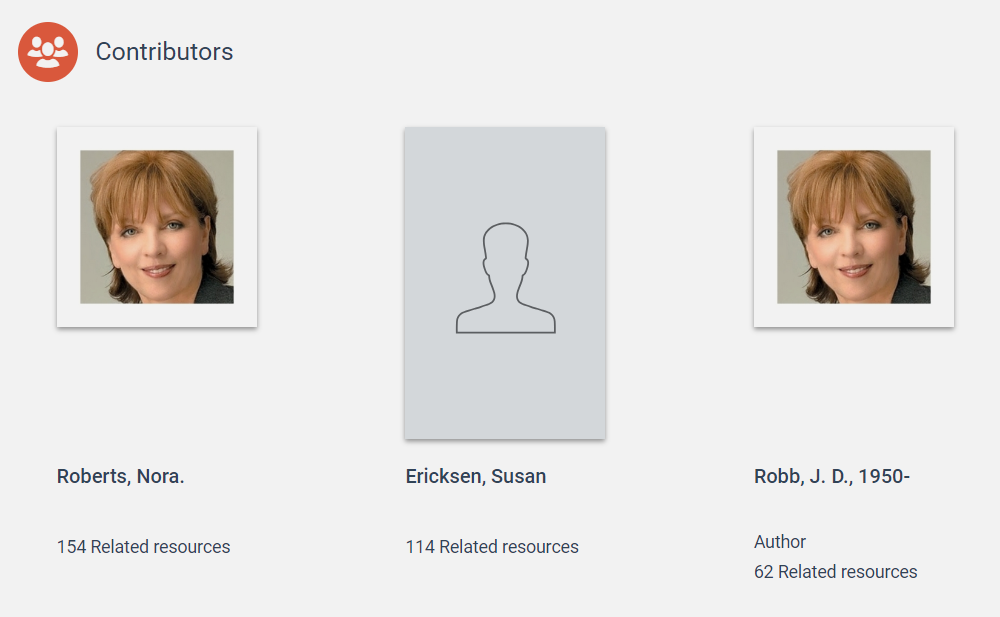
There's no argument that Nora Roberts is a "contributor", but the patron is left to guess why the same person is appearing twice in the list of contributors. Again, this isn't the best way of communicating this information.
Which is not to say that other systems do this any better. Las Vegas Clark County Library District (BiblioCore) has a poorly worded note; neither Frederick County Public Libraries (CARL•Connect) nor Montgomery County Public Libraries (Aspen) have any mention of Nora Roberts.
You can make the argument that the catalog data from these several examples would be just as confusing in any discovery layer, but I don't think that's true. For example, in CARL•Connect the author information in the 245 $c is included in an author search, but is not displayed. And details of layout matter. Typically, the controlled information from the 100 field will be at the top of the page, and clickable, while other data is displayed further down the page.
My point is not that Vega is worse than other discovery layers. Rather, its features rely more heavily on metadata being correct and complete. What Vega is doing in practice — displaying undifferentiated thumbnails generated from not-good-enough metadata — increases the likelihood of confusing patrons.
Conclusion
FRBR clearly benefits patrons because it can summarize different formats and availability in one place. But if different formats have different bibliographic data, is it the responsibility of the cataloger to provide the data which will accommodate the choices made by the OPAC software, or the responsibility of the software to make sense of the data provided by the catalog? Both!
For example, RDA relator terms help to make sense of contributors, but only if the OPAC displays something other than an unsorted list. Tracing a series will solve differences in a (transcribed) series name across formats and members of the series, but only if the OPAC handles 490 and 830 fields correctly and every item is traced.
There is work to do both for catalogers and OPAC vendors.
Notes
[1] For example, see Works, Expressions, Manifestations, Items: An Ontology by Karen Coyle for an explanation and some history.
[2] BiblioCore supports enhanced content from Syndetics Unbound, but I've never seen it in the wild.
Enjoyed the article as a Developer working for FCPL in Frederick. FCPL spent some time to revise CarlX ILS MARC Leader encoding level values and resolve some of the issues you encountered. The revisions use the CarlX ILS Catalog "macro" scripts that ought to run periodically as new titles arrive book distributors.